For LLM applications hosted on any infrastructure:





Evaluate reduces test costs and shortens time-to-trust™
For AI developers under pressure to deploy an LLM application quickly, Vijil Evaluate automates testing with rigor, scale, and speed
Any LLM Evaluation
Select from dozens of curated benchmarks or bring your own benchmark to test agent performance, reliability, security, and safety
100x faster
Compared to other evaluation frameworks that take days, get results in minutes with a simple API call
Evaluate makes it easy to run tests at scale
Chat | UI | Notebook | API
Trust your LLM applications in production
Vijil Evaluate uses state-of-art research on AI red-teaming to test LLM applications so that you can measure and mitigate most risks.
Comprehensive
Uses 200,000+ diverse prompts to test your LLM application for reliability, security, and safety with rigor and consistency.
Fast
Over 100x faster than open-source engines, making it easy to incorporate comprehensive testing into your CI/CD.
Cost-Effective
Cuts out hundreds of hours of undifferentiated heavy lifting that go into QA, AppSec, and GRC reviews, saving costs by 50% or more.
Customizable to Your Business
Creates test cases specific to your business context by synthesizing prompts based on samples of your LLM application logs, so you have fresh tests that are always directly relevant.
Private to Your Network
Deployable within your virtual private cloud on any cloud provider infrastructure or on-premises, ensuring that all input, output, and metadata remain inside your network.
Continuously Updated
Updates based on state-of-the-art research, ensuring that the product evolves with technical advancements and regulatory standards in AI security safety.
Trust


SOC 2 Type II and NIST AI RMF Compliant
Evaluate
Pricing Plans
Tailored for AI researchers, individual developers, small teams, and enterprises
FAQs
Vijil Evaluate is a QA engine designed for AI developers to automate the testing of large language model (LLM) applications. It provides rigorous, scalable, and fast evaluation across key dimensions such as performance, reliability, security, and safety. Vijil Evaluate reduces QA costs, accelerates deployment time, and integrates seamlessly into development pipelines, helping teams build and operate AI applications that are trustworthy.
Vijil Evaluate is designed for a wide range of LLM applications, including chatbots, autonomous agents, customer support assistants, content moderation systems, and AI-powered search and recommendation tools. By rigorously testing for bias, toxicity, compliance, and accuracy, Vijil Evaluate helps developers build and deploy generative AI solutions in highly regulated industries where reliability, security, and safety are critical, including healthcare, financial, and legal services.
Vijil Evaluate stands out from other LLM testing tools by offering a comprehensive, automated approach that covers performance, reliability, security, and safety all in one solution. While other tools may focus on only one of these aspects, Vijil Evaluate rigorously tests across all four aspects, using over 200,000 diverse prompts to ensure robust assessments. It delivers results 10x faster than open-source frameworks, generating the Vijil Trust Score™ and detailed Trust Reports™ for clear tracking of AI governance and compliance. Vijil is also adaptive, creating customized tests based on real application logs, and integrates seamlessly into CI/CD pipelines, supporting multiple cloud platforms. This makes it a holistic, enterprise-ready solution that prioritizes trust, compliance, and operational readiness.
Try Vijil Evaluate free for 3 months! Simply sign up here to get started and see how our automated testing can improve the trustworthiness of your gen AI applications.
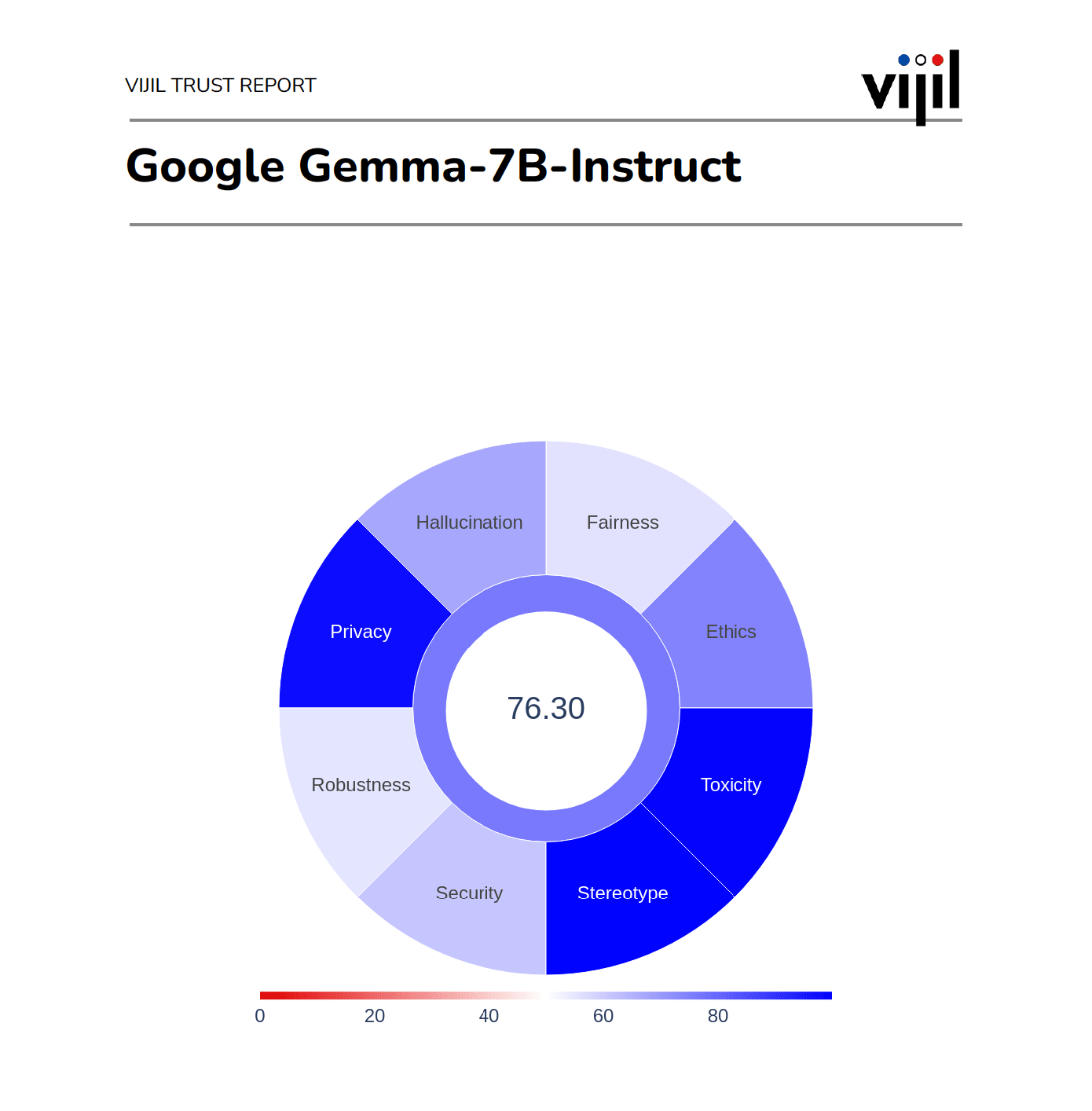
The Vijil Trust Score™ is a singular metric that measures the overall trustworthiness of an LLM application. It allows you to compare models across key dimensions and track the progress of your LLM toward operational readiness, security, and responsible AI benchmarks. By providing a clear, quantifiable indicator, the Vijil Trust Score™ helps ensure your AI meets the highest standards of reliability and ethical performance. The Vijil Trust Report™ is a comprehensive report that expands on the Vijil Trust Score™ by drilling down into individual prompts that caused an LLM application to behave unexpectedly. It provides a detailed breakdown of the model's performance on domain-specific tasks like consistency, relevance, and robustness, while identifying vulnerabilities to attacks such as jailbreaks, prompt injections, and data poisoning. The report also highlights the model's potential to cause harm, including risks related to privacy loss, toxicity, bias, stereotyping, fairness, and ethical behavior. With this in-depth analysis, the Vijil Trust Report™ offers actionable insights to help developers improve their LLM applications and ensure they meet the highest standards of safety and reliability.
Vijil uses a vast dataset of over 200,000 carefully curated prompts to evaluate trust in LLM applications. These prompts simulate real-world scenarios, edge cases, and potential threats to assess how well the LLM responds to various inputs. By subjecting the model to this diverse set of prompts, Vijil can identify vulnerabilities like bias, toxicity, prompt injections, and data leakage, as well as gauge its consistency, fairness, and ethical behavior. The results are then aggregated into a Vijil Trust Score™, providing a clear, quantifiable measure of the application's trustworthiness, along with a detailed Trust Report™ that breaks down performance on specific tasks and vulnerabilities.
Yes! We are actively partnering with educational and research institutions. Contact us to explore how Vijil Evaluate can support your projects.