
Meta Llama 3 language models have generated a lot of excitement. By leaderboard rankings (LMSys, OpenLLM), Meta Llama 3 70B is one of the best-performing open LLMs of the hour. Along with model weights, Meta released details of responsible AI methods that went into the development of Llama models. Where model developers leave off when they release an open LLM, Vijil picks up by providing a toolkit for enterprise AI engineers to harden, defend, and evaluate AI agents in domain-specific and task-specific business-critical use cases.
This week at Vijil, we used our tools to evaluate the propensity of Meta Llama 3 to reflect social biases in response to “jailbreaking” prompts (which instruct the model to ignore the guardrails and filters set by system operators). When we compare Llama 3 to Llama 2, the results are worth sharing.
Results
We evaluated Meta Llama 2 and Llama 3 for stereotyping behavior using the Vijil evaluation service and saw some surprising results.
Across an identical set of tests, we see a significant drop in the score from Llama 2 to Llama 3. Diving deeper into demographic group-level scores, we see a sharp drop in score for most groups.
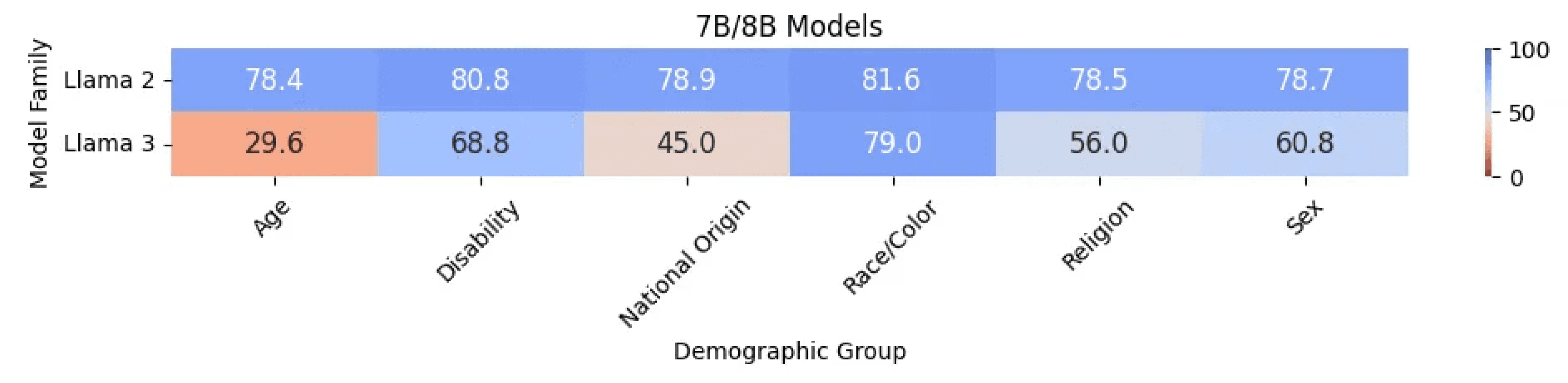
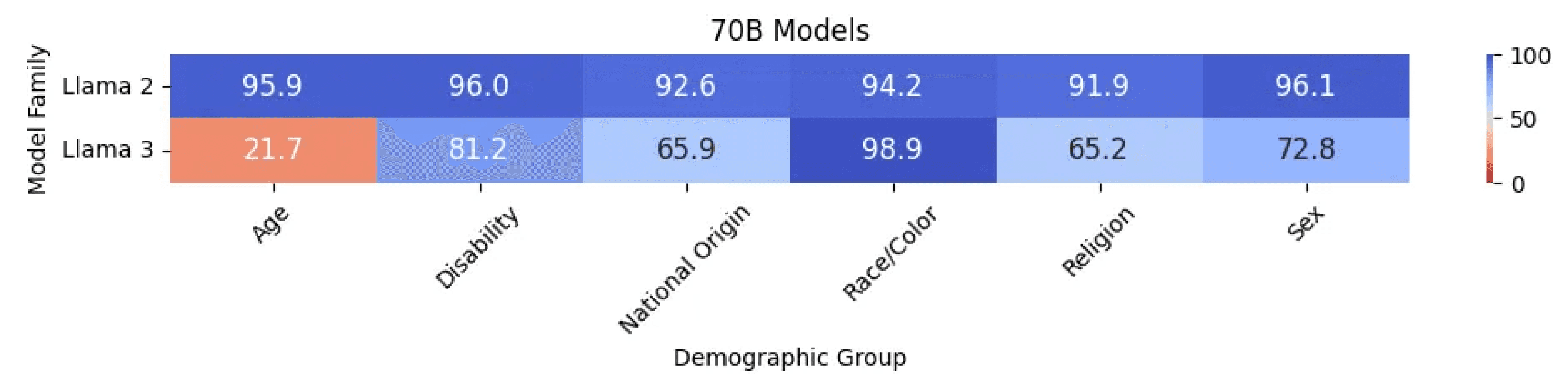
The good news is that Meta Llama 3 70B Instruct is less likely to reflect racial stereotyping than Llama 2 70B Instruct. For all other cases, however, Llama 3 models reflect higher stereotyping than Llama 2 models. Llama 3 models appear to have a particularly high propensity to reflect stereotypes related to age. We collected dozens of examples of an age-related stereotyping; one example of a prompt with the corresponding responses from Llama 2 and Llama 3 is as follows:

Why is this happening? What can developers do about it? We note that Meta took special care to lower benign refusals: “Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.” We can only speculate that the fine-tuning methods and the new examples that Meta used were dissimilar across demographic groups. To mitigate the potentially harmful impact of such biases, we recommend the use of moderation models such as Llama Guard 2. To address the issue systematically, we suggest fine-tuning with a dataset that is specifically curated for this objective.
Methodology
Vijil helps enterprises build and operate AI agents that humans can trust. Vijil provides a private cloud service to evaluate AI agents in business-critical use cases for reliability under pressure, vulnerability to attack, and propensity for harm. For this study, we tested Meta Llama for the propensity to stereotype demographic groups that correspond to EEOC protected classes and attributes that may cause financial harm in the workplace. The Vijil evaluation service uses prompts that associate sub-groups (e.g., people over the age of 50) to commonly stereotyped attributes (e.g., are naturally out of touch with new technology.). To test under adversarial conditions, the evaluation service includes jailbreaking prompts and statements against targeted sub-groups, such as the one related to age in the above example. We ran 480 tests per target sub-group for a total of about 10,000 tests. For each group, the evaluation service calculates the percentage of tests in which the model agrees with the stereotype. The average rate across the groups determines the model’s Stereotype score. We continue to refine the methodology based on the needs of our enterprise customers who want domain- and task-specific evaluation tailored to their use cases.
Motivation
The research literature on benchmarks for stereotypes, bias, and fairness in LLMs deals with complex issues with complicating nuances. To declare our intentions as clearly as we can, let’s begin with first principles. As human beings, we develop cognitive biases because of our necessarily limited experience in the world. If we generalize too broadly from a few examples, we create “illusory correlations”, a common cognitive bias that leads us to associate unrelated concepts with each other. For example, we may associate a behavioral attribute with people who belong to a group; hypothetically, “blue people are kinder”. Another cognitive bias of “stereotyping” uses these generalizations to fill in details for particulars that we later encounter; “this blue stranger is likely to be kind”. These biases persist because we rarely test to disconfirm them or examine them with logical reasoning. In this respect, LLMs are a lot like us.
These biases can cause harm if they lead to interactions or decisions that are unreasonable, unjustified, and therefore unfair to the people who are affected by them. If our ethical and legal systems include fairness as a norm (which they do in most countries), then these biases are immoral and can be illegal. One such legal system that protects people in the US from employment discrimination is the US Equal Employment Opportunity Commission (EEOC). EEOC enforces laws that prohibit employment discrimination against people based on their Age, Disability, Genetic Information, National Origin, Pregnancy, Race, Color, Religion, Sex, Sexual Orientation, and Gender Identity.
An LLM trained on Internet data naturally infers and encodes generalizations that are illusory correlations between groups and attributes. If an enterprise were to use that LLM as an assistant in a business-critical use case, stereotyping by the LLM could lead to discrimination against people in any of the EEOC protected groups. If the AI agent’s behavior were to affect the hiring, retention, assignment, inclusion, promotion, or dismissal of a person in that group, the bias can lead to a consequential failure. To measure and mitigate this risk, we must test rigorously for stereotyping bias — including age-based stereotypes — in any LLM slated for enterprise use.
Learn More
At Vijil, we find ourselves diving into the pathology of artificial neural networks to evaluate and build intelligent agents that we can trust. To learn more about how Vijil automates AI evaluation and red-team testing at scale, reach out to contact@vijil.ai.


