
Agentic AI holds the promise of transforming how work is done, and enterprises function. The challenge is how to transform that promise into tangible reality, where the demonstrable benefits consistently outweigh the known risks.
The challenge is complex, since the risks of agentic AI are intricately intertwined with the benefits.
On the benefits side of the equation, an agent can automate existing tasks, autonomously perform activities through reasoning for code completion, root cause analysis, customer interaction, transaction fulfillment, and incident response.
On the risk side of the equation, however, agents can fail in multiple and unanticipated ways: do the right thing the wrong way with cascading repercussions, stray from their original intent and hallucinate to inadvertently cause harm or financial damage, or be manipulated into doing the wrong thing like exposing data or set in motion malicious workflows.
The benefits side of the equation are driving momentum toward experimentation, while the risks stand in the way of deployment. According to a survey commissioned by Cisco Systems of 650 security, IT and line of business executives , 85% of organizations are already experimenting with, piloting, or deploying agentic AI. Yet, a meager 5% of respondents report having AI agents in broad production.

Often, projects are stalled because AI project stakeholders lack hard evidence that agents can avoid hallucinations, withstand prompt injections, resist jailbreak attempts, and adhere to corporate policies.
This is where the centrality of agent trustworthiness comes in. Agent trust should serve as a quantitative, objective measure for stakeholders from governance and security to development of where the agent is strong, where it’s vulnerable, and how it compares to alternatives. Without agent trust, agentic AI adoption is stalled, risky, or limited in scope.
Agent Trust is the bridge across the chasm
Agent trust is not binary, generic, nor static. The question is how much can you trust an agent based on multi-dimensional evaluation of its resilience, the specific risks and requirements of its environmental context, and what the organization decides is an acceptable risk threshold to deploy the agent.
With a repeatable, transparent approach to evaluate where the specific risks (whether business, technical or policy) lie before deployment to satisfy governance teams, and harden the agent against these specific risks in production to assuage security teams, agent owners can navigate between the promise and the reality.
Vijil defines a trusted agent as an agent that has been evaluated and scored for reliability, security, and safety - for its specific context, architecture, purpose, and the production conditions in which it will run. The relative importance of these dimensions vary based on which stakeholder is evaluating the agent - but represented as a composite trust score they are integral to understanding whether an agent can be trusted enough for its task, environment, and business outcome.
An objective, quantifiable trust score serves as the evidence that engineering, governance, security and risk teams can assess to determine how the agent stacks up against standards for agent behavior and monitor agents as they evolve to meet them.
However agent trust degrades over time because of unanticipated failures in production. Either novel prompt injection techniques, indirect retrieval exploits, and tool-misuse patterns emerge between audit cycles; or, emergent agent behavior produces hallucinations, inaccuracies or other failures. With the trust score protections acting as a baseline for observability in production, security teams can use telemetry and attack data to propose targeted improvements to restore the trust score, or recommend a higher trust score for resilience against vulnerability to new attack techniques and tool access exploits.

Evaluating, protecting and maintaining agent trust, therefore, involves an ongoing process across the agentic lifecycle:
- Customize evaluation across multiple scenarios to produce an objective trust score metric that provides a baseline and audit-ready documentation specific to the agent
- Harden the agent with protections for the reliability, security, and safety risks identified in the evaluation process
- Validate that protections like guardrails improve the trust score before deployment
- Continuously improve agent trust by treating every blocked attack as a learning opportunity, generating fixes for security to review and agent developers to apply
Unpacking the dimensions of agent trust
Reliability measures whether an agent performs correctly under normal conditions. Security measures whether it maintains that performance when someone is actively trying to break it. Safety asks a different question: even when the agent is functioning correctly, does it stay within acceptable boundaries?
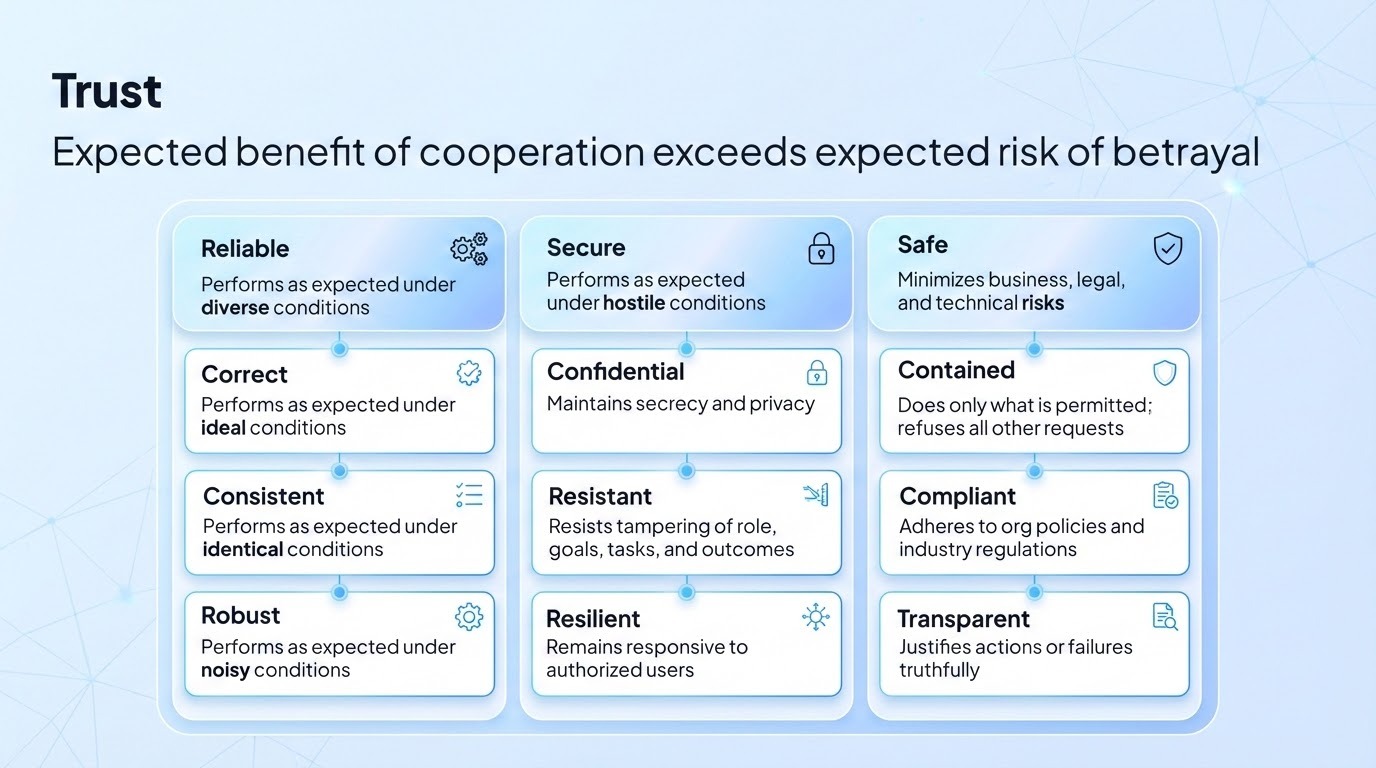
Reliability: Measuring whether agents do what they’re supposed to do—correctly, consistently, and robustly.
Reliability measures alignment between expected and actual behavior. A reliable agent produces correct outputs, behaves consistently across similar conditions, and remains robust under diverse inputs. Reliability failures include hallucinations (fabricating information), logical errors (flawed reasoning chains), and brittleness (sensitivity to input rewording). These failures erode confidence in the agent’s outputs even when it isn’t under attack.
Security: Measuring whether agents can resist adversarial attacks on confidentiality, integrity, and availability.
Security failures are adversarial by nature. Someone is trying to make the agent do something it shouldn’t—leak data, follow unauthorized instructions, or become unavailable, such as a single prompt resulting in a LLM context window flooding attacks. These attacks, both prompt injections and jailbreaks to manipulate LLM output, exploit the underlying mechanics and probabilistic nature of language models of how LLMs and agents interact in ways that traditional software security doesn’t anticipate.
As is the case with other dimensions of agentic trust, but especially security, agents present a conceptual challenge. Security control models are deterministic, but agents behave probabilistically.
Generic filters and guardrails can address some obvious risks like leaking PII, and enforce declarative policies for topic constraints. However, these guardrails are a partial answer to the question of how an agent defends itself in production contexts and roles.
Safety: Measuring whether agents operate within acceptable boundaries and minimize harm when things go wrong.
Safety failures often emerge from the agent doing too much—generating harmful content, making unauthorized decisions, accessing data it shouldn’t, or operating beyond its intended role and intent. These failures matter most when agents have real-world impact: interacting with customers, accessing systems, or making recommendations that affect people’s lives.
Safety is especially relevant in the context of compliance requirements and ethical considerations such as fairness and transparency - is the agent making a biased decision on data that is personally identifiable data collected without user context.
Trust is a matter of context
Trust is a composite of how an agent scores against these three dimensions - a quantifiable, objective score that is specific to the agent’s intent and context, and allows stakeholders to measure against internally defined risk thresholds.
How can you traverse the chasm?
AI agents face adversarial pressure constantly. Users probe for vulnerabilities. Attackers craft inputs designed to extract information or hijack behavior. Competitors test for weaknesses. The public internet is an adversarial environment, and any agent exposed to it will encounter attempts to compromise it.
The challenges that organizations face in moving into production point to the limitations of existing approaches:
- AI Security 1.0
- Can discover, profile and assess agents. However, these tools do not integrate into the development process to evaluate whether agents are trusted before deployment, and only apply guardrails when untrusted agents are already in production. Guardrails prove to be too brittle to adapt to real-world environments
- AI Governance
- Can define governance frameworks, policies and controls. However, these tools can’t evaluate whether agents in development and running in production conform to these policies, and can’t enforce guardrails and controls that are derived from governance policies. Also, governance and risk policies typically are only updated after a new threat vector or jailbreak technique is identified.
- AI Observability
- Can monitor and detect performance and reliability issues in production. However, these tools can’t evaluate agents across the trust spectrum before deployment, and don’t enforce security hardening or compliance for reasoning steps
- AI Testing
- Can scan for vulnerabilities, and LLM security and reliability issues. However, these provide a point in time scan of the system, don’t provide insights into how the agent will function and interact in production conditions, and can’t be used to assess risk factors that are specific to the agent and its purpose.
Bridging the trust gap can’t be a piecemeal or generic approach: it should encompass the agentic lifecycle, align with cross-functional processes and outcomes, operate independently of both where agents are built and where agents run, and be customized to the agent’s context, associated personas, and intent.
How Vijil Helps: Shipping with Trust
Vijil helps teams clearly define what constitutes a trusted agent, validate against custom policies, and ensure there is an ongoing feedback loop from production to development for improving resilience.
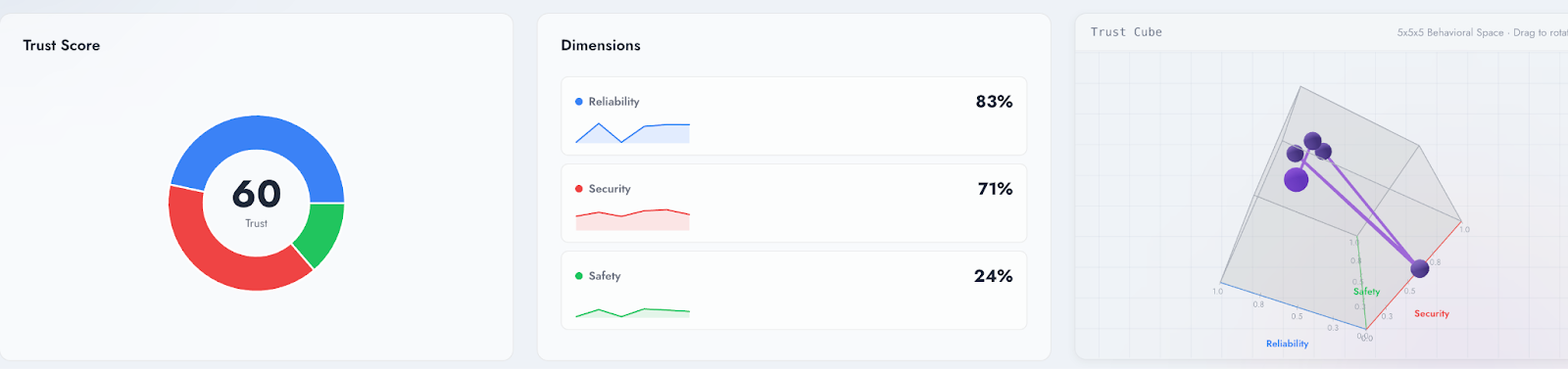
Vijil provides a platform designed to measurably improve the reliability, security, and safety of agents across their lifecycle. Developers and engineering teams use Vijil Diamond to automate testing in hours of customizable policies for business, compliance, and risk requirements, across hundreds of scenarios. The outcome is a data-driven, quantifiable Trust Score that engineering teams and stakeholders like legal, risk and governance teams can use for objective assessment, whether in terms of reliability, risk thresholds, and acceptable safety boundaries.
Security and engineering teams use Vijil Dome to automatically translate evaluation policies into guardrails to maintain the Trust Score - ensuring that runtime protection operates to minimize failures the testing identified - as well as contain security risks and prevent compliance violations. Dome can also address compliance use cases, including real-time monitoring for active threats and generating reports for audits.
Darwin, in turn, learns from this production telemetry and proposes targeted improvements to agent instructions, configuration, and source code, which developers can quickly review, apply, and evaluate.
These three capabilities work as an integrated system - from evaluation to protection to improvement, and looping back to re-evaluation, not point solutions. The insights and data gleaned from each attack can be leveraged to make agents stronger. Each improvement is validated before deployment. Resilience and trust become continuous, measurable, and auditable.
For more details, read how Vijil cuts time to trust, and dig deeper into our platform.


