
One of the key themes at QCon AI event in Boston this week was Governance: Ensuring security and compliance in non-deterministic systems.
In his session at QCon, Vijil founding ML engineer Anuj Tambwekar focused on why this challenge exists from a technical perspective, and what are the practical approaches to addressing them to maintain a systematic, scalable lifecycle.
At Vijil, we often see that the question holding agents back from production isn't capability—it's trust.
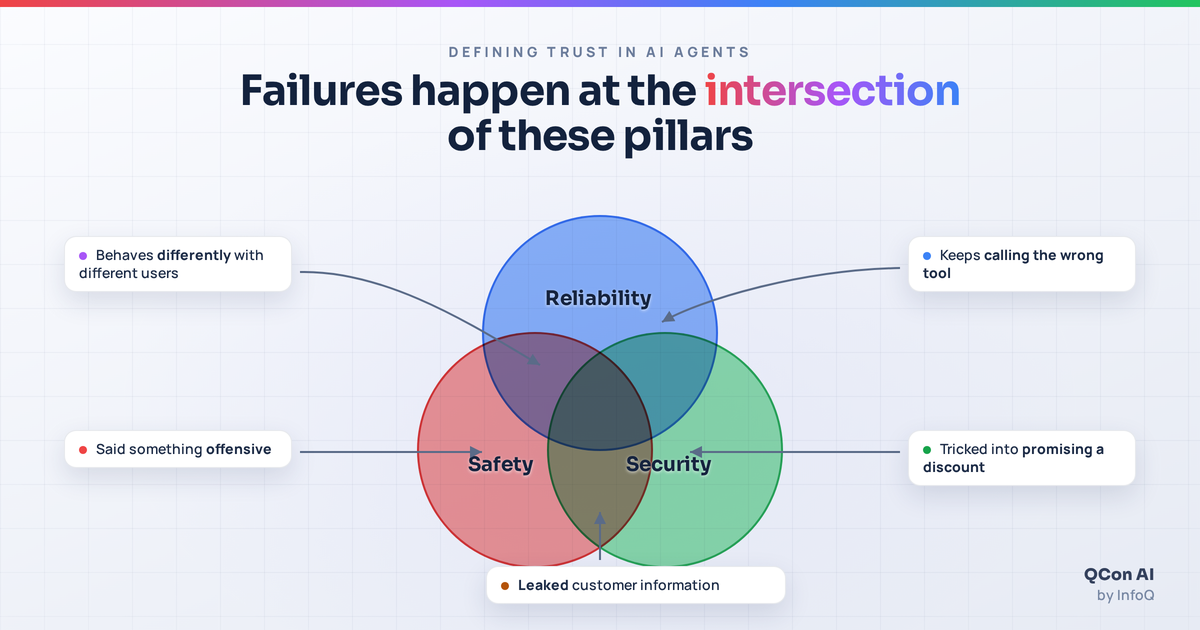
Trust is worth defining precisely: the expected benefit of relying on an agent has to exceed the expected risk of it betraying you. That bar rests on three pillars, and the most damaging failures sit where they overlap:
Reliability is trust under normal conditions. Because LLMs are stochastic, an agent that answers well once may not answer well again, and reaching for a model where a deterministic tool would do erodes trust fast. You earn reliability by grounding responses in trusted context and by measuring consistency—pass at K across repeated runs, not a single green test—so you trust the behavior, not the luck. Don’t get LLMs to do math if you have a better way to handle it.
Safety is trust that the agent won't cause harm. You don't need an attacker for this to break; subtle linguistic bias or an over-broad mandate can damage users on its own. Trust here comes from giving the agent a scoped identity, hardening its system prompt so it knows what's in and out of bounds, and enforcing moderation guardrails rooted in explicit policy. Guardrails don’t have to apply to just the agent - they can be applied to tool calls and actions too.
Security is trust under hostile conditions. Prompt injection, indirect jailbreaks, and goal hijacking turn a trusted agent into a liability—especially one that can act on the world. Trust is preserved by probing every surface that touches an LLM, testing components independently, and granting minimal permissions.
A robust security strategy blends off-the-shelf red-teaming with component-level testing and goal-driven adversarial simulation.
Crucially, trust is not a launch-day verdict—it decays. New jailbreaks and CVEs surface monthly and behavior drifts, so trust has to be monitored as a live signal. Treat telemetry as non-negotiable, trace everything, and turn every production failure into a new test case so your evaluation suite keeps pace with reality. When trust does slip, treat the fix as an experiment: generate candidate changes, spin up variants, re-evaluate against a dedicated suite, and promote the one that scores highest. No single model earns trust for every job; let the data decide which model serves which step.
Tying it all together, trust becomes a lifecycle rather than a milestone: build, evaluate, deploy, monitor, and improve, with production signals flowing back into your evals. Run that loop continuously and trust stops being a gut feeling. It becomes a measurable, governable property—your real go/no-go for shipping.
Full presentation is available here.

.png)
