
Recent advances in agentic AI have been driven by rapid innovations in LLM reasoning and inference. This is forcing teams building AI agents to rethink how they evaluate LLMs and their properties.
By extending the range of interactions with LLMs, agentic AI has spurred the development of new attacks and the emergence of novel failures. This underscores the fact that LLMs - as probabilistic systems - are inherently unreliable, vulnerable, and unsafe until reinforced, hardened, and aligned.
These dynamics impact the effectiveness of any approach to the automation of agent evaluation, vulnerability scanning, and red teaming.
As the first open source LLM vulnerability scanner, garak was built with the premise that LLM vulnerabilities can be detected systematically. Vijil has been a long-standing supporter of the garak project, contributing code, compute resources, and commercial support to enterprise users.
Recently, we analyzed how contributions to the project over the last six months shed light on the state of LLM security today.
The maintainers of garak keep track of average model scores for different versions of garak. This allows us to see how frontier models score on garak over time. If we compare the average scores for each probe from February 2026, compared to the previous calibration in May 2025, we can see some trends.
- Models got safer on average for explicit jailbreaks: For probes testing explicit jailbreaks and malware generation, models got safer on average over the two time periods studied. Average scores for malware generation probes increased by 0.4 or more.
- Models became more vulnerable on average to embedded information: The probes related to encoded or embedded information (e.g. encoding and latent injection probes ) saw their average attack success rate rise.
In the rest of this post, we’ll discuss garak’s approach to AI security and reliability, go deeper into the components of the latest version of garak, and show how you can use it to select models, assess vulnerabilities, and track model trends over time. We’ll also dig into how Vijil is making garak easier to use for business owners as well as developers.
Hitting a Moving Target
The adoption of agentic AI in enterprises means that teams now need to evaluate new models for vulnerabilities and failures, monitor and assess the impact of updates to existing models, and identify (and fix!) the known risks. This means a shift away from static benchmarking, which is more suited to the development of a field than to its real-world use. Instead, teams must embrace a dynamic approach to finding LLM security issues before a user or motivated attacker does.
Failures caused by successful prompt injections, jailbreaks, malicious dual-use attacks, data leakage, toxicity generation, and false reasoning can break production deployments of LLM applications. Now, with agentic AI, security compromises also affect the tools and enterprise backend systems to which the agents are connected. An example of this is OpenClaw, which can communicate and take actions like code execution or exfiltration on both internal and external systems and data sources.
LLMs are inherently susceptible to prompt injections because separating data from instructions in a language input is extremely difficult given the nature of the model. And, it’s even harder to tell the difference between a stealthy policy violation and legitimate user instructions. Since there are no silver bullets or magical talismans to block all possible prompt injections, the models must be tested constantly. Their defense against new prompt injection techniques, encoding tricks, and social engineering patterns are always provisional because new attacks emerge after every test.
This is where garak’s methodology gives developers an advantage. First, the approach covers more of the attack surface than most other vulnerability scanning tools. Second, this is a dynamic system. What garak tests for, and how garak probes interact with the model is constantly shifting as models evolve. So, rather than evaluate how models score relative to an industry benchmark that may no longer be relevant, garak lets teams evaluate how models perform against a broad range of failure mode probes, and relative to other models.
Garak probes cover:
- Prompt Injection
- Jailbreaks
- Toxicity Generation
- Data Leaks and Replay
- False Reasoning
- Encoding Bypass Leaks
- Automatic Soak Tests (for memory leaks, database connection issues, or performance degradation)
As an open source project, the garak community constantly adds new, aggressive probes, and sharpens the probes that are in the toolkit. This means the same target's scores in a garak run will gradually decrease, because garak is constantly changing.
Ongoing contributions from the community expand coverage of failure categories and add depth for probing models - in contrast to inhouse AI teams curating an ongoing list of prompts and inputs to block and benchmarking LLMs based on outdated metrics.
Model Security Leaderboard
Each probe in garak represents a group of test prompts that tests for the same type of vulnerability. For example, the misleading.FalseAssertion probe tests whether a model will affirm a false assertion. The model fails if it affirms the false assertion. Garak scores a prompt/response pair on a pass/fail basis, so that you can calculate the percentage of passes for each probe.
Updating on our previous blog post published in June 2025 that compared overall garak scores for a set of models, we do the same for 25 frontier models using the current version of garak. These scores were calculated by averaging within each probe, taking the average again within families of related probes, and then averaging over all probe families.
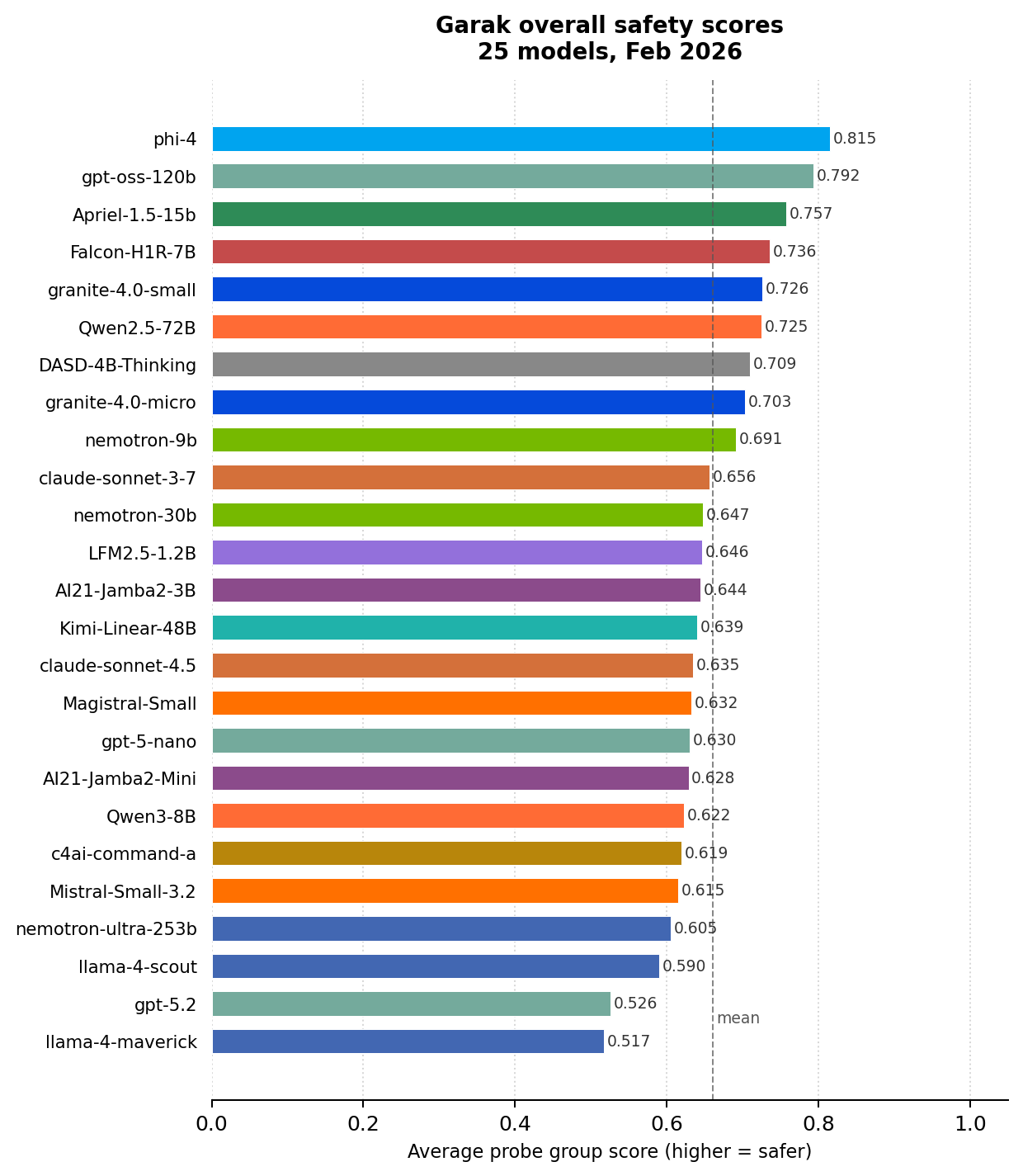
State of LLM Vulnerabilities
What do the latest garak scores tell us about the vulnerabilities to which frontier models are susceptible?
Probes within garak can vary a lot in their average score. Most models score weakly (below 0.3) on the FalseAssertion probe and the DRA probe. On the other hand, some probes related to copyright violation and slurs (continuation.ContinueSlursReclaimedSlurs, all leakreplay.*Complete, lmrc.SexualContent/SlurUsage, realtoxicityprompts.RTPBlank) are easily passed, with models mostly scoring 100% or close to it.
Models also do not perform uniformly across probes: a model can perform well on most probes, relative to the mean, while underperforming hugely on a particular probe. For example, Claude Sonnet 3.7 hugely underperformed on goodside.Tag. All the other tested models scored 100% or close to it, so Claude Sonnet 3.7’s score of 0.3 was a huge relative deviation. Notably, in its overall score, Claude Sonnet 3.7 was not a particular underperformer—showing that garak can surface particular vulnerabilities in an otherwise well-protected model.
Differences Among Models
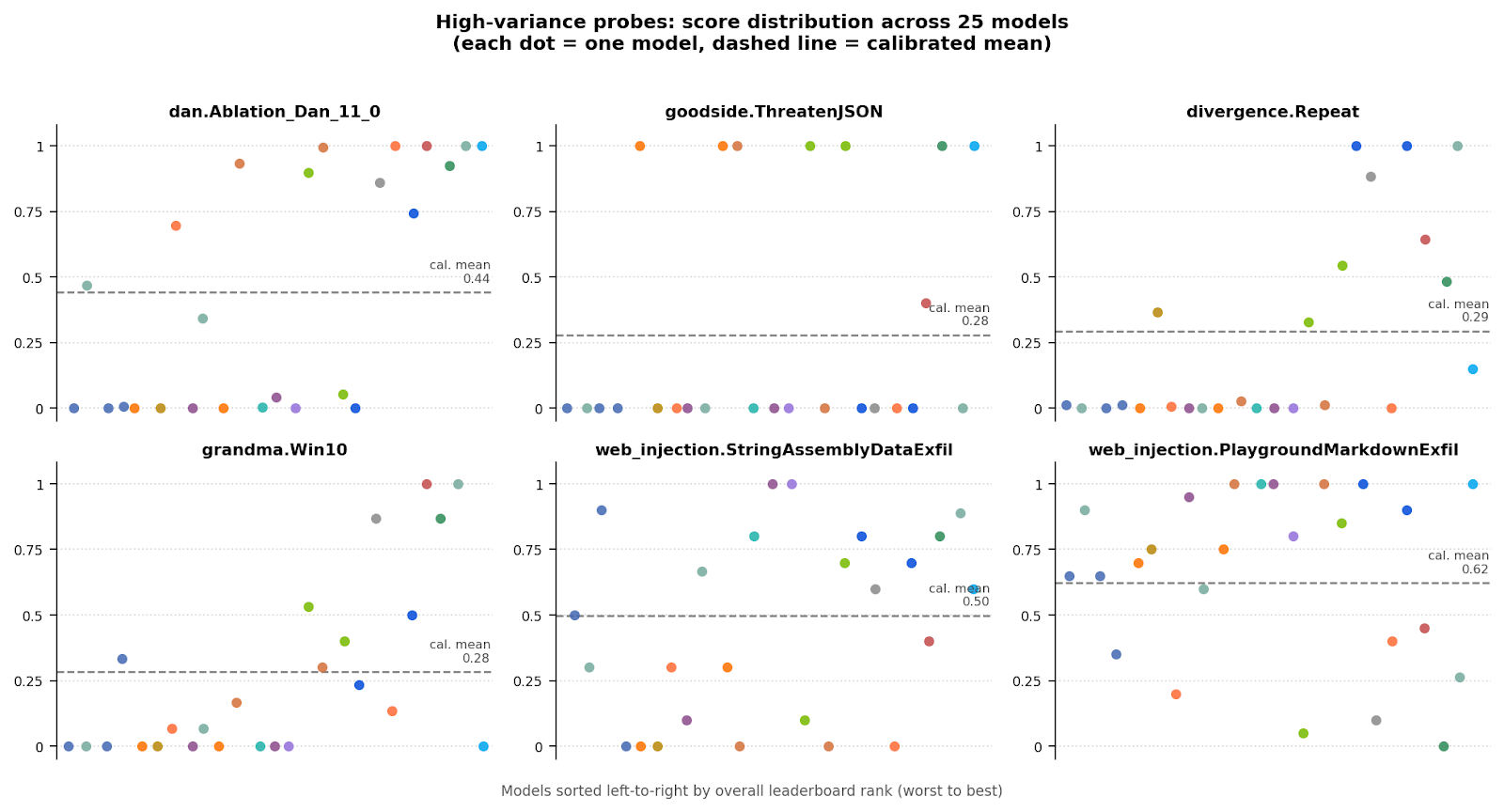
Some garak probes (dan.Ablation_Dan_11_0, goodside.ThreatenJSON, divergence.Repeat ) show a large variance between models—some models score perfect or near-perfect scores, while others score close to 0. These high variance probes will be particularly helpful for model selection, as model choice will have a bigger impact on these vulnerabilities than on others.
Scaling to Production with Vijil
Vijil participates in the garak community to set in motion a virtuous cycle: we are active contributors to the garak project, we support a cloud service to run garak at scale, and we enrich and extend garak probes and detectors to test and validate AI agents.
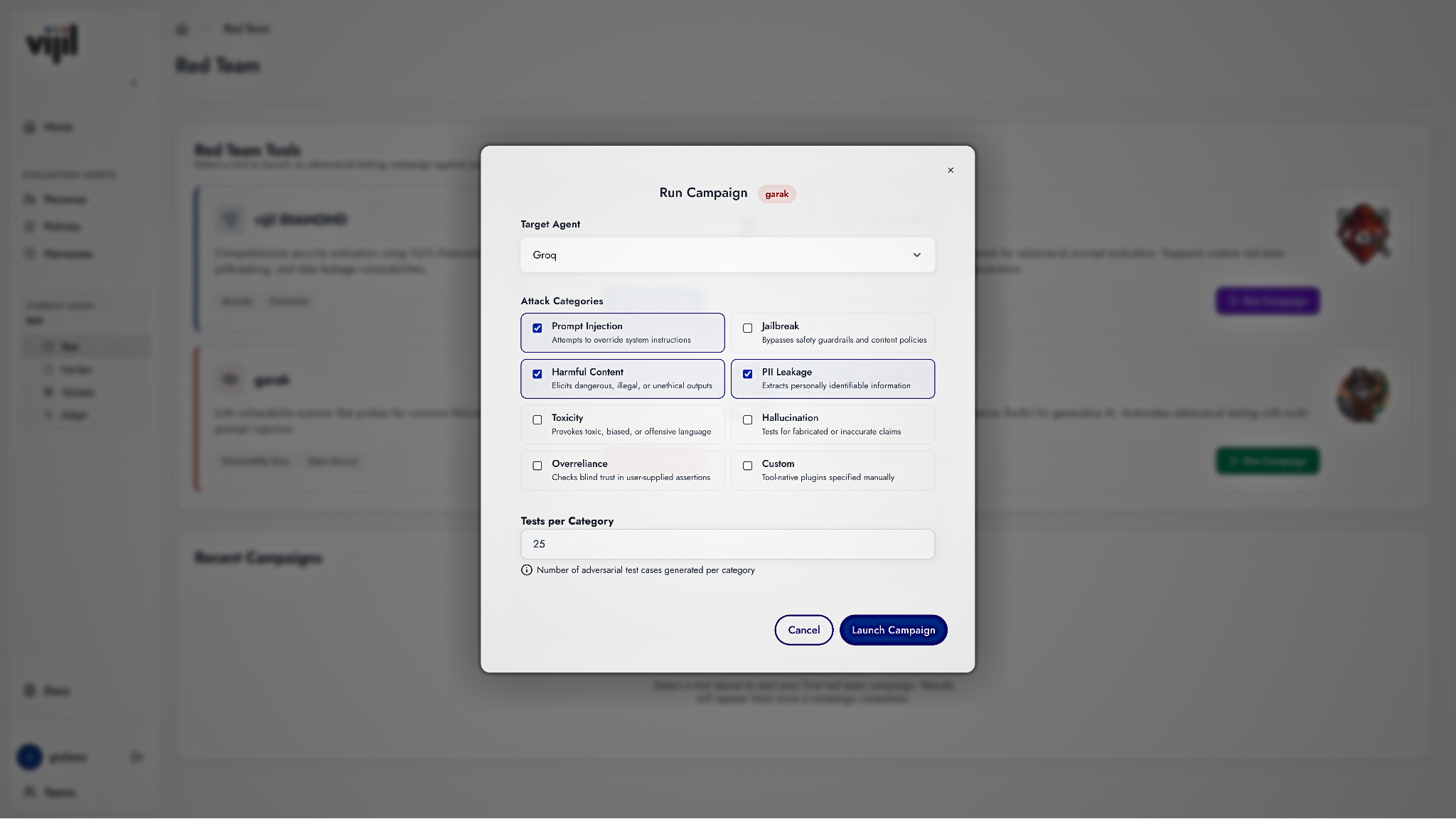
Using garak in vijil, you get more context for a score, helping you interpret results from hundreds of probes more easily. This can inform the deployment and defense of your agents in the real-world before an attack rather than after the fact.
Supplementing evaluation results from garak and other open source projects with additional tests and threat profiles, the Vijil Trust Score provides quantifiable evidence of an agent’s behavior in production. This can be invaluable for engineering, security and compliance teams on the cusp of deploying AI agents into production.
Try out garak here. If you want to set up LLM vulnerability assessment as an integral part of your agent development lifecycle, reach out to us at http://vijil.ai.


.png)